Data Cleaning
Overview
Teaching: 0 min
Exercises: 120 minQuestions
How to convert dates to ISO?
How to match scientific names to WoRMS?
How to convert latitudes and longitudes to decimal degrees?
Objectives
Aligning dates to the ISO 8601 standard.
Matching scientific names to WoRMS.
Converting latitude and longitude variations to decimal degrees North and East.
Now that you know what the mapping is between your raw data and the Darwin Core standard, it’s time to start cleaning up the data to align with the conventions described in the standard. The following activities are the three most common conversions a dataset will undergo to align to the Darwin Core standard:
- Ensuring dates follow the ISO 8601 standard
- Matching scientific names to an authoritative resource
- Ensuring latitude and longitude values are in decimal degrees
Below is a short summary of each of those conversions as well as some example conversion scripts. The exercises are intended to give you a sense of the variability we’ve seen in datasets and how we went about converting them. While the examples use the pandas package for Python and the tidyverse collection of packages for R (in particular the lubridate package), those are not the only options for dealing with these conversions but simply the ones we use more frequently in our experiences.
Getting your dates in order
Dates can be surprisingly tricky because people record them in many different ways. For our purposes we must follow
ISO 8601 which means using a four digit year, two digit month, and two digit
day with dashes as separators (i.e. YYYY-MM-DD). You can also record time in ISO 8601 but make sure to include the time
zone which can also get tricky if your data take place across time zones and throughout the year where daylight savings
time may or may not be in effect (and start and end times of daylight savings vary across years). There are packages in
R and Python that can help you with these vagaries. Finally, it is possible to record time intervals in ISO 8601 using a
slash (e.g. 2022-01-02/2022-01-12). Examine the dates in your data to determine what format they are following and what
amendments need to be made to ensure they are following ISO 8601. Below are some examples and solutions in Python and R
for them.
ISO 8601 dates can represent moments in time at different resolutions, as well as time intervals, which use “/” as a separator. Date and time are separated by “T”. Timestamps can have a time zone indicator at the end. If not, then they are assumed to be local time. When a time is UTC, the letter “Z” is added at the end (e.g. 2009-02-20T08:40Z, which is the equivalent of 2009-02-20T08:40+00:00).
Tip
Focus on getting your package of choice to read the dates appropriately. While you can use regular expressions to replace and substitute strings to align with the ISO convention, it will typically save you time if you work in your package of choice to translate the dates.
| Darwin Core Term | Description | Example |
|---|---|---|
| eventDate | The date-time or interval during which an Event occurred. For occurrences, this is the date-time when the event was recorded. Not suitable for a time in a geological context. | 1963-03-08T14:07-0600 (8 Mar 1963 at 2:07pm in the time zone six hours earlier than UTC).2009-02-20T08:40Z (20 February 2009 8:40am UTC).2018-08-29T15:19 (3:19pm local time on 29 August 2018).1809-02-12 (some time during 12 February 1809).1906-06 (some time in June 1906).1971 (some time in the year 1971).2007-03-01T13:00:00Z/2008-05-11T15:30:00Z (some time during the interval between 1 March 2007 1pm UTC and 11 May 2008 3:30pm UTC).1900/1909 (some time during the interval between the beginning of the year 1900 and the end of the year 1909).2007-11-13/15 (some time in the interval between 13 November 2007 and 15 November 2007). |
Examples in Python
When dealing with dates using pandas in Python it is best to create a Series as your time column with the appropriate datatype. Then, when writing your file(s) using .to_csv() you can specify the format which your date will be written in using the
date_formatparameter.The examples below show how to use the pandas.to_datetime() function to read various date formats. The process can be applied to entire columns (or Series) within a DataFrame.
01/31/2021 17:00 GMTThis date follows a typical date construct of
month/day/year24-hour:minutetime-zone. The pandas.to_datetime()function will correctly interpret these dates without theformatparameter.import pandas as pd df = pd.DataFrame({'date':['01/31/2021 17:00 GMT']}) df['eventDate'] = pd.to_datetime(df['date'], format="%m/%d/%Y %H:%M %Z") dfdate eventDate 01/31/2021 17:00 GMT 2021-01-31 17:00:00+00:00
31/01/2021 12:00 ESTThis date is similar to the first date but switches the
monthanddayand identifies a differenttime-zone. The construct looks likeday/month/year24-hour:minutetime-zoneimport pandas as pd df = pd.DataFrame({'date':['31/01/2021 12:00 EST']}) df['eventDate'] = pd.to_datetime(df['date'], format="%d/%m/%Y %H:%M %Z") dfdate eventDate 31/01/2021 12:00 EST 2021-01-31 12:00:00-05:00
January, 01 2021 5:00 PM GMTimport pandas as pd df = pd.DataFrame({'date':['January, 01 2021 5:00 PM GMT']}) df['eventDate'] = pd.to_datetime(df['date'],format='%B, %d %Y %I:%M %p %Z') dfdate eventDate January, 01 2021 5:00 PM GMT 2021-01-01 17:00:00+00:00
1612112400in seconds since 1970This uses the units of
seconds since 1970which is common when working with data in netCDF.import pandas as pd df = pd.DataFrame({'date':['1612112400']}) df['eventDate'] = pd.to_datetime(df['date'], unit='s', origin='unix') dfdate eventDate 1612112400 2021-01-31 17:00:00
44227.708333333333This is the numerical value for dates in Excel because Excel stores dates as sequential serial numbers so that they can be used in calculations. In some cases, when you export an Excel spreadsheet to CSV, the dates are preserved as a floating point number.
import pandas as pd df = pd.DataFrame({'date':['44227.708333333333']}) df['eventDate'] = pd.to_datetime(df['date'].astype(float), unit='D', origin='1899-12-30') dfdate eventDate 44227.708333333333 2021-01-31 17:00:00.000000256Observations with a start date of
2021-01-30and an end date of2021-01-31.Here we store the date as a duration following the ISO 8601 convention. In some cases, it is easier to use a regular expression or simply paste strings together:
import pandas as pd df = pd.DataFrame({'start_date':['2021-01-30'], 'end_date':['2021-01-31']}) df['eventDate'] = df['start_date']+'/'+df['end_date'] dfstart_time end_time eventDate 2021-01-30 2021-01-31 2021-01-30/2021-01-31
Examples in R
When dealing with dates using R, there are a few base functions that are useful to wrangle your dates in the correct format. An R package that is useful is lubridate, which is part of the
tidyverse. It is recommended to bookmark this lubridate cheatsheet.The examples below show how to use the
lubridatepackage and format your data to the ISO-8601 standard.
01/31/2021 17:00 GMTlibrary(lubridate) date_str <- '01/31/2021 17:00 GMT' date <- lubridate::mdy_hm(date_str,tz="UTC") date <- lubridate::format_ISO8601(date) # Separates date and time with a T. date <- paste0(date, "Z") # Add a Z because time is in UTC. date[1] "2021-01-31T17:00:00Z"
31/01/2021 12:00 ESTlibrary(lubridate) date_str <- '31/01/2021 12:00 EST' date <- lubridate::dmy_hm(date_str,tz="EST") date <- lubridate::with_tz(date,tz="UTC") date <- lubridate::format_ISO8601(date) date <- paste0(date, "Z") date[1] "2021-01-31T17:00:00Z"
January, 01 2021 5:00 PM GMTlibrary(lubridate) date_str <- 'January, 01 2021 5:00 PM GMT' date <- lubridate::mdy_hm(date_str, tz="GMT") lubridate::with_tz(date,tz="UTC") lubridate::format_ISO8601(date) date <- paste0(date, "Z") date[1] "2021-01-01T17:00:00Z"
1612112400in seconds since 1970This uses the units of
seconds since 1970which is common when working with data in netCDF.library(lubridate) date_str <- '1612112400' date_str <- as.numeric(date_str) date <- lubridate::as_datetime(date_str, origin = lubridate::origin, tz = "UTC") date <- lubridate::format_ISO8601(date) date <- paste0(date, "Z") date[1] "2021-01-31T17:00:00Z"
44227.708333333333This is the numerical value for dates in Excel because Excel stores dates as sequential serial numbers so that they can be used in calculations. In some cases, when you export an Excel spreadsheet to CSV, the dates are preserved as a floating point number.
library(openxlsx) library(lubridate) date_str <- 44227.708333333333 date <- as.Date(date_str, origin = "1899-12-30") # If you're only interested in the YYYY-MM-DD fulldate <- openxlsx::convertToDateTime(date_str, tz = "UTC") fulldate <- lubridate::format_ISO8601(fulldate) fulldate <- paste0(fulldate, "Z") print(date) print(fulldate)[1] "2021-01-31" [1] "2021-01-31T17:00:00Z"Observations with a start date of
2021-01-30and an end date of2021-01-31. For added complexity, consider adding in a 4-digit deployment and retrieval time.Here we store the date as a duration following the ISO 8601 convention. In some cases, it is easier to use a regular expression or simply paste strings together:
library(lubridate) event_start <- '2021-01-30' event_finish <- '2021-01-31' deployment_time <- 1002 retrieval_time <- 1102 # Time is recorded numerically (1037 instead of 10:37), so need to change these columns: deployment_time <- substr(as.POSIXct(sprintf("%04.0f", deployment_time), format = "%H%M"), 12, 16) retrieval_time <- substr(as.POSIXct(sprintf("%04.0f", retrieval_time, format = "%H%M"), 12, 16) # If you're interested in just pasting the event dates together: eventDate <- paste(event_start, event_finish, sep = "/") # If you're interested in including the deployment and retrieval times in the eventDate: eventDateTime_start <- lubridate::format_ISO8601(as.POSIXct(paste(event_start, deployment_time), tz = "UTC")) eventDateTime_start <- paste0(eventDateTime_start, "Z") eventDateTime_finish <- lubridate::format_ISO8601(as.POSIXct(paste(event_finish, retrieval_time), tz = "UTC")) eventDateTime_finish <- paste0(eventDateTime_finish, "Z") eventDateTime <- paste(eventDateTime_start, eventDateTime_finish, sep = "/") print(eventDate) print(eventDateTime)[1] "2021-01-30/2021-01-31" [1] "2021-01-30T10:02:00Z/2021-01-31T11:02:00Z"
Tip
When all else fails, treat the dates as strings and use substitutions/regular expressions to manipulate the strings into ISO 8601.
Matching your scientific names to WoRMS
OBIS uses the World Register of Marine Species (WoRMS) as the taxonomic backbone for
its system. GBIF uses the Catalog of Life. Since WoRMS contributes to the Catalog of
Life and WoRMS is a requirement for OBIS we will teach you how to do your taxonomic lookups using WoRMS. The key Darwin
Core terms that we need from WoRMS are scientificNameID also known as the WoRMS LSID which looks something like this
"urn:lsid:marinespecies.org:taxname:105838" and kingdom but you can grab the other parts of the taxonomic hierarchy if
you want as well as such as taxonRank.
There are two ways to grab the taxonomic information necessary. First, you can use the WoRMS Taxon Match Tool. The tool accepts lists of scientific names (each unique name as a separate row in a .txt, .csv, or .xlsx file) up to 1500 names and provides an interface for selecting the match you want for ambiguous matches. A brief walk-through using the service is included below. A more detailed step-by-step guide on using the WoRMS Taxon Match Tool for the MBON Pole to Pole can be found here.
The other way to get the taxonomic information you need is to use worrms (yes there are two r’s in the package name) or pyworms.
| Darwin Core Term | Description | Example |
|---|---|---|
| scientificNameID | An identifier for the nomenclatural (not taxonomic) details of a scientific name. | urn:lsid:ipni.org:names:37829-1:1.3 |
| kingdom | The full scientific name of the kingdom in which the taxon is classified. | Animalia, Archaea, Bacteria, Chromista, Fungi, Plantae, Protozoa, Viruses |
| taxonRank | The taxonomic rank of the most specific name in the scientificName. | subspecies, varietas, forma, species, genus |
Using the WoRMS Taxon Match Tool
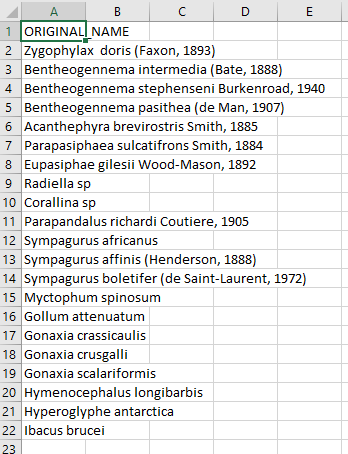
Create a CSV (comma separated value) file with the scientific name of the species of interest. Here we are showing some of the contents of the file
species.csv.- Upload that file to the WoRMS Taxon match service
- make sure the option LSID is checked
- for the example file, make sure you select LineFeed as the row delimiter and Tab as the column delimiter
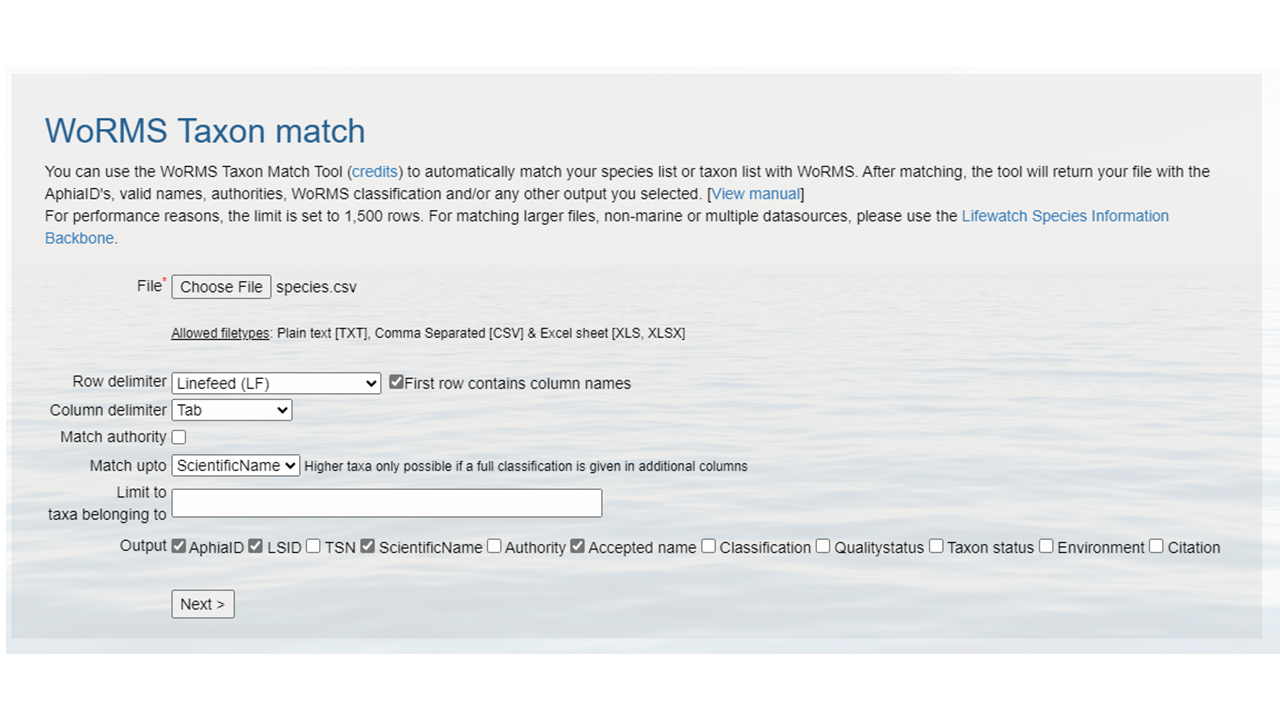
Identify which columns to match to which WoRMS term.
Click
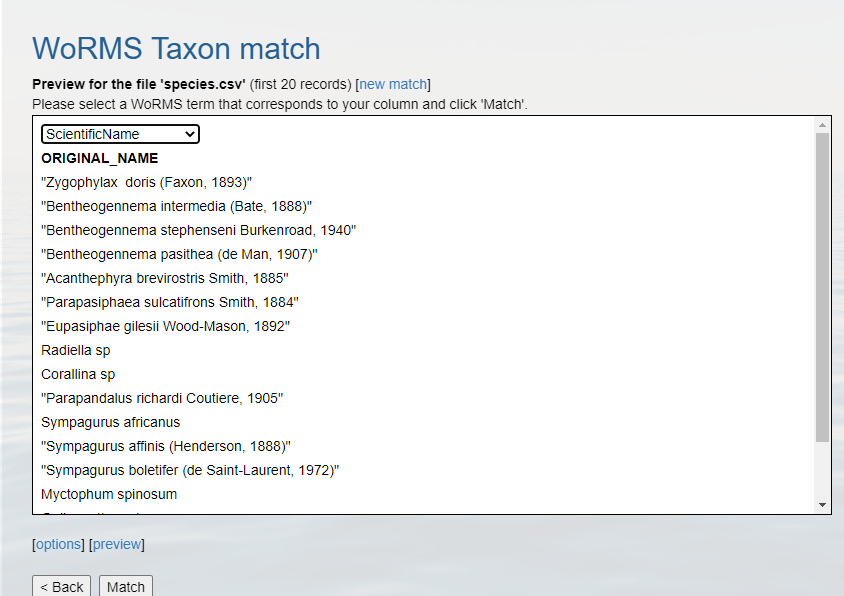
MatchHopefully, a WoRMS exact match will return
- In some cases you will have ambiguous matches. Resolve these rows by using the pull down menu to select the appropriate match.
- Non-matched taxa will appear in red. You will have to go back to your source file and determine what the appropriate text should be.
- Download the response as an XLS, XLSX, or text file and use the information when building the Darwin Core file(s). The response from the example linked above can be found here. A screenshot of the file can be seen below:
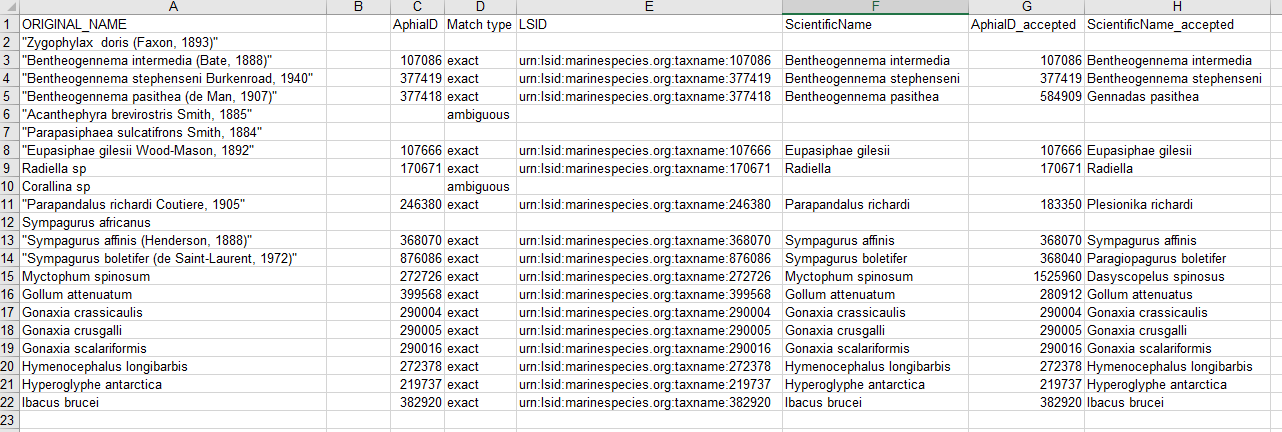
Using the worrms R package
- Carcharodon carcharias (White shark)
library(worrms) worms_record <- worrms::wm_records_taxamatch("Carcharodon carcharias", fuzzy = TRUE, marine_only = TRUE)[[1]] worms_record$lsid; worms_record$rank; worms_record$kingdom[1] "urn:lsid:marinespecies.org:taxname:105838" [1] "Species" [1] "Animalia"
Using the pyworms python package
Bringing in
species.csvand collecting appropriate information from WoRMS using the pyworms package.Note some of the responses have multiple matches, so the user needs to evaluate which match is appropriate.
import pandas as pd import pyworms import pprint fname = 'https://ioos.github.io/bio_mobilization_workshop/data/species.csv' # Read in the csv data to data frame df = pd.read_csv(fname) # Iterate row by row through the data frame and query worms for each ScientificName term. for index, row in df.iterrows(): resp = pyworms.aphiaRecordsByMatchNames(row['ORIGINAL_NAME'], marine_only=True) # When no matches are found, print the non-matching name and move on if len(resp[0]) == 0: print('\nNo match for name "{}"'.format(row['ORIGINAL_NAME'])) continue # When more than 1 match is found, the user needs to take a look. But tell the user which one has multiple matches elif len(resp[0]) > 1: print('\nMultiple matches for name "{}":'.format(row['ORIGINAL_NAME'])) pprint.pprint(resp[0], indent=4) continue # When only 1 match is found, put the appropriate information into the appropriate row and column else: worms = resp[0][0] df.loc[index, 'scientificNameID'] = worms['lsid'] df.loc[index, 'taxonRank'] = worms['rank'] df.loc[index, 'kingdom'] = worms['kingdom'] # print the first 10 rows df.head()No match for scientific name "Zygophylax doris (Faxon, 1893)" Multiple matches for scientific name "Acanthephyra brevirostris Smith, 1885" ORIGINAL_NAME scientificNameID taxonRank kingdom 0 Zygophylax doris (Faxon, 1893) NaN NaN NaN 1 Bentheogennema intermedia (Bate, 1888) urn:lsid:marinespecies.org:taxname:107086 Species Animalia 2 Bentheogennema stephenseni Burkenroad, 1940 urn:lsid:marinespecies.org:taxname:377419 Species Animalia 3 Bentheogennema pasithea (de Man, 1907) urn:lsid:marinespecies.org:taxname:377418 Species Animalia 4 Acanthephyra brevirostris Smith, 1885 NaN NaN NaN
Getting lat/lon to decimal degrees
Latitude (decimalLatitude) and longitude (decimalLongitude) are the geographic coordinates (in decimal degrees north and east, respectively), using the spatial reference system given in geodeticDatum of the geographic center of a location.
decimalLatitude, positive values are north of the Equator, negative values are south of it. All values lie between -90 and 90, inclusive.decimalLongitude, positive values are east of the Greenwich Meridian, negative values are west of it. All values lie between -180 and 180, inclusive.
Note, that the requirement for decimalLatitude and decimallLongitude is they must be in decimal degrees in WGS84. Since this is the requirement for Darwin Core, OBIS and GBIF will assume data shared using those Darwin Core terms are in the geodetic datum WGS84. We highly recommend checking the coordinate reference system (CRS) of your observations to confirm they are using the same datum and documenting it in the geodeticDatum Darwin Core term. If your coordinates are not using WGS84, they will need to be converted in order to share the data to OBIS and GBIF since decimalLatitude and decimalLongitude are required terms.
Helpful packages for managing CRS and geodetic datum:
Tip
If at all possible, it’s best to extract out the components of the information you have in order to compile the appropriate field. For example, if you have the coordinates as one lone string
17° 51' 57.96" S 149° 39' 13.32" W, try to split it out into its component pieces:17,51,57.96,S,149,39,13.32, andWjust be sure to track which values are latitude and which are longitude.
| Darwin Core Term | Description | Example |
|---|---|---|
| decimalLatitude | The geographic latitude (in decimal degrees, using the spatial reference system given in geodeticDatum) of the geographic center of a Location. Positive values are north of the Equator, negative values are south of it. Legal values lie between -90 and 90, inclusive. | -41.0983423 |
| decimalLongitude | The geographic longitude (in decimal degrees, using the spatial reference system given in geodeticDatum) of the geographic center of a Location. Positive values are east of the Greenwich Meridian, negative values are west of it. Legal values lie between -180 and 180, inclusive. | -121.1761111 |
| geodeticDatum | The ellipsoid, geodetic datum, or spatial reference system (SRS) upon which the geographic coordinates given in decimalLatitude and decimalLongitude as based. | WGS84 |
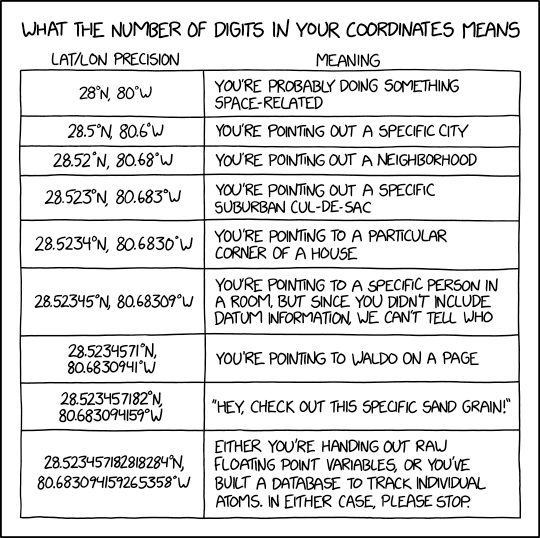 Image credit: xkcd
Image credit: xkcd
Examples in Python
17° 51' 57.96" S149° 39' 13.32" W
- This example assumes you have already split the two strings into discrete components (as shown in the table). An example converting the full strings
17° 51' 57.96" S149° 39' 13.32" Wto decimal degrees can be found here.
lat_degrees lat_minutes lat_seconds lat_hemisphere lon_degrees lon_minutes lon_seconds lon_hemisphere 17 51 57.96 S 149 39 13.32 W df = pd.DataFrame({'lat_degrees':[17], 'lat_minutes':[51], 'lat_seconds':[57.96], 'lat_hemisphere':['S'], 'lon_degrees': [149], 'lon_minutes': [39], 'lon_seconds':[13.32], 'lon_hemisphere': ['W'], }) df['decimalLatitude'] = df['lat_degrees'] + ( (df['lat_minutes'] + (df['lat_seconds']/60) )/60) df['decimalLongitude'] = df['lon_degrees'] + ( (df['lon_minutes'] + (df['lon_seconds']/60) )/60) # Convert hemisphere S and W to negative values as units should be `degrees North` and `degrees East` df.loc[df['lat_hemisphere']=='S','decimalLatitude'] = df.loc[df['lat_hemisphere']=='S','decimalLatitude']*-1 df.loc[df['lon_hemisphere']=='W','decimalLongitude'] = df.loc[df['lon_hemisphere']=='W','decimalLongitude']*-1 df[['decimalLatitude','decimalLongitude']]decimalLatitude decimalLongitude -17.8661 -149.653733° 22.967' N117° 35.321' W
- Similar to above, this example assumes you have already split the two strings into discrete components (as shown in the table).
lat_degrees lat_dec_minutes lat_hemisphere lon_degrees lon_dec_minutes lon_hemisphere 33 22.967 N 117 35.321 W df = pd.DataFrame({'lat_degrees':[33], 'lat_dec_minutes':[22.967], 'lat_hemisphere':['N'], 'lon_degrees': [117], 'lon_dec_minutes': [35.321], 'lon_hemisphere': ['W'], }) df['decimalLatitude'] = df['lat_degrees'] + (df['lat_dec_minutes']/60) df['decimalLongitude'] = df['lon_degrees'] + (df['lon_dec_minutes']/60) # Convert hemisphere S and W to negative values as units should be `degrees North` and `degrees East` df.loc[df['lat_hemisphere']=='S','decimalLatitude'] = df.loc[df['lat_hemisphere']=='S','decimalLatitude']*-1 df.loc[df['lon_hemisphere']=='W','decimalLongitude'] = df.loc[df['lon_hemisphere']=='W','decimalLongitude']*-1 df[['decimalLatitude','decimalLongitude']]decimalLatitude decimalLongitude 0 33.382783 -117.588683
Examples in R
17° 51' 57.96" S149° 39' 13.32" W
lat_degrees lat_minutes lat_seconds lat_hemisphere lon_degrees lon_minutes lon_seconds lon_hemisphere 17 51 57.96 S 149 39 13.32 W library(tibble) tbl <- tibble(lat_degrees = 17, lat_minutes = 51, lat_seconds = 57.96, lat_hemisphere = "S", lon_degrees = 149, lon_minutes = 39, lon_seconds = 13.32, lon_hemisphere = "W") tbl$decimalLatitude <- tbl$lat_degrees + ( (tbl$lat_minutes + (tbl$lat_seconds/60)) / 60 ) tbl$decimalLongitude <- tbl$lon_degrees + ( (tbl$lon_minutes + (tbl$lon_seconds/60)) / 60 ) tbl$decimalLatitude = as.numeric(as.character(tbl$decimalLatitude))*(-1) tbl$decimalLongitude = as.numeric(as.character(tbl$decimalLongitude))*(-1)> tbl$decimalLatitude [1] -17.8661 > tbl$decimalLongitude [1] -149.6537
33° 22.967' N117° 35.321' W
lat_degrees lat_dec_minutes lat_hemisphere lon_degrees lon_dec_minutes lon_hemisphere 33 22.967 N 117 35.321 W library(tibble) tbl <- tibble(lat_degrees = 33, lat_dec_minutes = 22.967, lat_hemisphere = "N", lon_degrees = 117, lon_dec_minutes = 35.321, lon_hemisphere = "W") tbl$decimalLatitude <- tbl$lat_degrees + ( tbl$lat_dec_minutes/60 ) tbl$decimalLongitude <- tbl$lon_degrees + ( tbl$lon_dec_minutes/60 ) tbl$decimalLongitude = as.numeric(as.character(tbl$decimalLongitude))*(-1)> tbl$decimalLatitude [1] 33.38278 > tbl$decimalLongitude [1] -117.5887
33° 22.967' N117° 35.321' W
- Using the measurements package the
conv_unit()can work with space separated strings for coordinates.
lat lat_hemisphere lon lon_hemisphere 33 22.967 N 117 35.321 W tbl <- tibble(lat = "33 22.967", lat_hemisphere = "N", lon = "117 35.321", lon_hemisphere = "W") tbl$decimalLongitude = measurements::conv_unit(tbl$lon, from = 'deg_dec_min', to = 'dec_deg') tbl$decimalLongitude = as.numeric(as.character(tbl$decimalLongitude))*(-1) tbl$decimalLatitude = measurements::conv_unit(tbl$lat, from = 'deg_dec_min', to = 'dec_deg')> tbl$decimalLatitude [1] 33.38278 > tbl$decimalLongitude [1] -117.5887
Key Points
When doing conversions it’s best to break out your data into it’s component pieces.
Dates are messy to deal with. Some packages have easy solutions, otherwise use regular expressions to align date strings to ISO 8601.
WoRMS LSIDs are a requirement for OBIS.
Latitude and longitudes are like dates, they can be messy to deal with. Take a similar approach.